Overview
SPIDER X is a comprehensive content discovery tool designed to uncover hidden or undocumented web resources. It employs a multi-faceted approach, including a sophisticated headless web crawler, various URL gathering techniques, and targeted bruteforcing capabilities. By systematically exploring web applications, SPIDER X can reveal potential security vulnerabilities, sensitive information exposure, and unintended access points. This tool is invaluable for thorough security assessments, helping to map out the complete attack surface of web applications and identify areas that may require further security hardening.Usage Examples
You can specify a list of target URLs for SPIDER X to find hidden links, endpoints, files and application routes. Optionally, you may configure any settings you’d like. Afterward, simply click on Scan to launch your scan. Shortly after your scan has been launched, you will be redirected to the page to view your pending scan.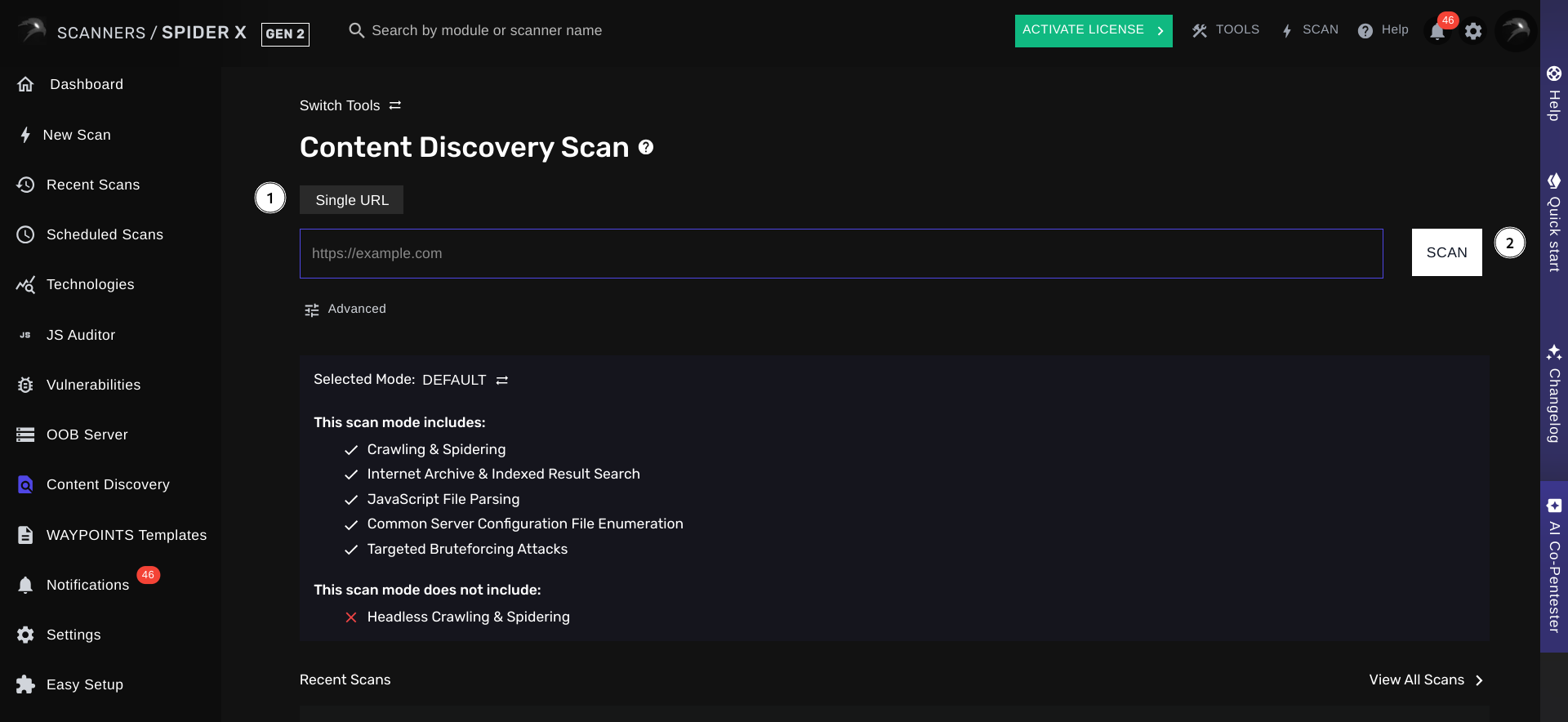
Scanner settings
This scanner accepts the following optional parameters:Scan mode
To help you quickly scan targets with a pre-set configuration, we’ve decided to introduce Scan Modes. The following 5 scan modes are available:Default
The Default Scan Mode is the most used and most preferred. This scan mode performs every supported content discovery method, including targeted bruteforcing, except headless crawling.Advanced
The Advanced Scan Mode employs just like the default scan mode, every supported content discovery method. This scan mode will perform headless crawling too.Crawl
The Crawl Scan Mode is configured to crawl your target but will avoid bruteforcing (forced browsing).Headless Crawl
The Headless Crawl Scan Mode is configured to perform headless crawling on your target. It will avoid performing any bruteforcing (forced browsing).Fuzzer
The Fuzzer Scan Mode is configured to only perform targeted bruteforcing on your list of targets.External sources
SPIDER X is capable of leveraging external sources, such as internet archives, to discover more content.JavaScript parsing
SPIDER X is capable of enumerating and parsing JavaScript files to discover more content via hard-coded references, such as links, URLs and URIs. JavaScript files are goldmines for penetration testers like you, for this sole reason, this option is enabled by default. We recommend you keep this option enabled whenever possible to increase your probability of discovering more content on your target.Auto-submit forms
SPIDER X can be deployed as a (headless) web crawler. This option instructs the content discovery tool to submit forms.Filter targets
The URL filter can help you reduce noise and remove 404 pages.Skip SSL/TLS certificate validation
Some targets may have incorrectly or invalid issued SSL/TLS certificates. If your target has an invalid SSL/TLS certificate and can be trusted, you can override this option to turn off SSL/TLS certificate validation.Capabilities
SPIDER X is a comprehensive content discovery scanner equipped with the following capabilities:Headless Crawling
Headless Crawling
SPIDER X is capable of deploying a headless web browser to perform headless crawling. This method mimics a pentester’s behavior as it crawls and intercepts all pages using a headless crawler and a valid user agent.
Finds Exponentially More
Finds Exponentially More
SPIDER X employs various methods to help find you exponentially more interesting results compared to other traditional content discovery tools. Methods include (headless) web crawling, targeted bruteforcing (forced browsing), request intercepting, JavaScript file enumeration and in-page client-side code parsing, and leveraging of external sources + common server configuration files.
Mimics a Pentester's Behavior
Mimics a Pentester's Behavior
When configured, SPIDER X deploys a headless web browser to perform headless crawling while simultaneously intercepting all background network requests that your target may emit.
Targeted Bruteforcing (Forced Browsing)
Targeted Bruteforcing (Forced Browsing)
When configured, SPIDER X can perform targeted bruteforcing. A wordlist will be prepared for the identified technologies on your target with the intent to increase your chances of finding more content.
Client-Side Parameter Intercepting For DOM-Based Vulnerability Detection
Client-Side Parameter Intercepting For DOM-Based Vulnerability Detection
When configured, SPIDER X deploys a headless web browser to perform headless crawling while simultaneously intercepting events emitted by custom client-side code and web APIs that your target may use. This can help you find parameters that may have been processed by the DOM, increasing your chances of finding potential DOM-based security vulnerabilities.
Built-in URL Filter
Built-in URL Filter
With the built-in URL filter, you can easily reduce noise and remove 404 pages.
Authenticated Content Discovery Scanning
Authenticated Content Discovery Scanning
Authenticated content discovery scanning is supported. Follow the Global Configuration instruction guide to learn more about how to set custom authentication HTTP request headers.